 When setting a custom renderer to a
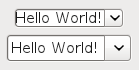
When setting a custom renderer to a JComboBox, the usual way is to extend a DefaultListCellRenderer and override the getListCellRendererComponent() method. However, this may lead to ugly comboboxes on some Look and Feels. As you can see on the top combobox, it is rendered considerably smaller and with the letters sticked to the left border, just by using a DefaultListCellRenderer. The Look and Feel seems to use a special renderer class for proper rendering, as it is shown in the combobox below.
A solution is to use a proxy ListCellRenderer instead, which only converts the value and then delegates the rendering to the original renderer. For example:
public class ListCellRendererProxy implements ListCellRenderer {
private final ListCellRenderer delegate;
public ListCellRendererProxy(ListCellRenderer delegate) {
this.delegate = delegate;
}
@Override
public Component getListCellRendererComponent(JList list, Object value,
int index, boolean isSelected, boolean cellHasFocus) {
// modify the value here...
return delegate.getListCellRendererComponent(list, value, index, isSelected, cellHasFocus);
}
}
The renderer proxy can be used like this:
JComboBox cbx = new JComboBox();
ListCellRenderer oldRenderer = cbx.getRenderer();
cbx.setRenderer(new ListCellRendererProxy(oldRenderer));
The combobox items are now converted to a string by a custom cell renderer, but are still rendered by the original renderer implementation of the current Look and Feel. However, while a single DefaultListCellRenderer instance can be shared with many JComboBox, a new renderer proxy needs to be instanciated per combobox.