AmigaOS was an operating system that was way ahead of its time. It had features that other home operating systems (like Windows or MacOS) were missing back then, like preemptive multitasking. There was also a feature that was called assignments. I truly miss that one on Linux!
An Amiga "assign" is a bit similar to the drive letter you may know from Windows. For example, the Windows path C:\example.txt refers to a file called example.txt in the root directory of the main partition, while the same file on the first floppy drive is called A:\example.txt.
On Amiga, the main partition is usually called DH0:, the second partition is called DH1: and so on, while the first floppy drive is called DF0:. A similar path on the Amiga would thus be DH0:example.txt or DF0:example.txt.
As you can see, on the Amiga a "drive letter" can actually consist of multiple characters and also numbers. This is called an assignment. The name DH0 is assigned to the main harddisk partition.
But wait, there is more!
You can have multiple assigns pointing to the same target. For example, the main partition usually contains the Amiga desktop environment, called Workbench. For this reason, the main partition also has a label like Workbench, and the file could also be accessed as Workbench:example.txt.
This is actually quite a smart concept, especially for exchangeable media. For example, let's imagine we have just started a game called shredzone, and it needs to access a file Music/Opening.mod on its installation disk (AmigaOS uses a slash as file separator, like all proper operating systems). It would open a file called shredzone:Music/Opening.mod.
AmigaOS would see that there is no assignment called shredzone, and would pop up a dialog like this:
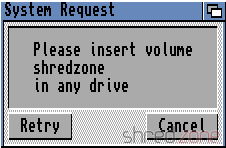
From a user's perspective, I would now know that I have to find a medium called shredzone, and insert it into the computer. It does not matter if it's a floppy disk, a CD, or even a network mount. AmigaOS also does not command me to insert the medium into a certain drive. If it's a floppy disk, and I have multiple floppy drives, I can just pick the one I like to. AmigaOS will then detect that a medium with that name was inserted, would close the dialog, and grant the game access to the file.
On Linux, I would need to access that medium under a path like /run/media/shred/shredzone, which is a lot to type, contains my user name, and is harder to remember than just shredzone:.
But wait, there is still more! 😄
It is easy to add assignments to the system via command line. It's even possible to use subdirectories as assignment target. Let's stay with our shredzone game example. I got tired of having to insert the installation disk every time I want to play that game. So I create a directory called DH2:Games/Shredzone/Files on my hard drive, and I copy all files of that disk to that directory.
After that, I enter this command on the command line:
assign shredzone: DH2:Games/Shredzone/Files
Now, when I start the game, AmigaOS will see that there is a shredzone assign already existing, and will access the files there. So the song file shredzone:Music/Opening.mod would be accessed at DH2:Games/Shredzone/Files/Music/Opening.mod.
AmigaOS makes use of assigns itself. For example, there is a standard assignment called C:. It usually points to the C directory of the booting device, where all command line commands (like dir, copy, delete etc) are expected to be present. This assign is similar to what $PATH is to a Linux shell.
Imagine I have installed a set of development tools, like an assembler and a C compiler. The commands of this toolset can be found at DH1:Development/DevTools/C. On a Linux system, I would add this path to the $PATH env variable, so I can just type the command name to execute one of these commands.
On AmigaOS, I just add this path to an existing assignment:
assign add C: DH1:Development/DevTools/C
Now AmigaOS knows that when I enter a command in the command line, it has to look for it in Workbench:C, and if it's not found there, it will try to find it in DH1:Development/DevTools/C. I could even execute commands like dir C:, and see all files in both directories. Of course, it is not limited to two targets.
There is still more, like deferred assigns. But I only want to give you a general impression of what Amiga assigns are, and why I miss them on Linux.