 In der Anfangszeit der Heimcomputer, zu Beginn der 1980er Jahre, waren Festplatten und sogar Disketten für den Heimgebrauch zu teuer. Der günstigste Weg, große Datenmengen zu speichern, war die Kassette. Kassetten und Kassettenrekorder waren erschwinglich und in fast jedem Haushalt verfügbar.
In der Anfangszeit der Heimcomputer, zu Beginn der 1980er Jahre, waren Festplatten und sogar Disketten für den Heimgebrauch zu teuer. Der günstigste Weg, große Datenmengen zu speichern, war die Kassette. Kassetten und Kassettenrekorder waren erschwinglich und in fast jedem Haushalt verfügbar.
In diesem Blogartikel werde ich dir erklären, wie der Sinclair ZX Spectrum Programme auf Kassetten speicherte. Andere Heimcomputer jener Zeit, wie der Commodore 64 oder der Amstrad CPC, funktionierten ähnlich.
Kassetten waren dafür gedacht, Audiosignale wie Sprache oder Musik zu speichern, also mussten die Erfinder der Heimcomputer einen Weg finden, Daten in Audiosignale umzuwandeln. Der einfachste Weg ist, die Daten in einen Bitstrom aus 1en und 0en zu serialisieren und einen langen Rechteckwellenzyklus für “1” und einen kurzen Rechteckwellenzyklus für “0” zu erzeugen. Genau das macht der ZX Spectrum tatsächlich!
Ein kurzer Wellenzyklus wird erzeugt, indem der Audioausgang für 855 sogenannte T-States mit Strom versorgt wird und der Strom dann für weitere 855 T-States abgeschaltet wird. Ein “T-State” ist die Zeit eines einzelnen Taktimpulses der Z80-A CPU. Da die CPU eines klassischen ZX Spectrum mit 3,5 MHz getaktet ist, hat ein T-State eine Dauer von 286 ns. Die Dauer eines kurzen Wellenzyklus beträgt somit 489 µs, was eine Audiofrequenz von etwa 2.045 Hz ergibt. Der lange Wellenzyklus ist einfach doppelt so lang.
Aufgrund allerlei Filter im analogen Audiopfad wird das rechteckige Signal bei der Wiedergabe zu einem sinusförmigen Signal geglättet. Ein Schmitt trigger in der Hardware des ZX Spectrum wandelt das Audiosignal wieder in eine rechteckige Form um. Da das Audiosignal unterschiedliche Amplituden haben oder sogar invertiert sein kann, achtet die Hardware nur auf Signalflanken, nicht auf Pegel. Alles, was die Laderoutine jetzt noch tun muss, ist, die Dauer der Impulse zu messen, den Bitstrom zu regenerieren und die Bytes wieder zusammenzusetzen.
Wenn du denkst, dass die Dinge nicht so einfach sein können, hast du recht. 😄 Der schwierigste Teil für den Lader ist es, den Anfang des Bitstroms zu finden. Wenn er auch nur um einen Zyklus (oder sogar nur um einen Impuls) abweicht, verschieben sich alle Bytes um ein Bit und das Ergebnis ist unbrauchbar. Jegliches Rauschen auf dem Band macht es jedoch unmöglich, einfach auf den Beginn des Signals zu warten.
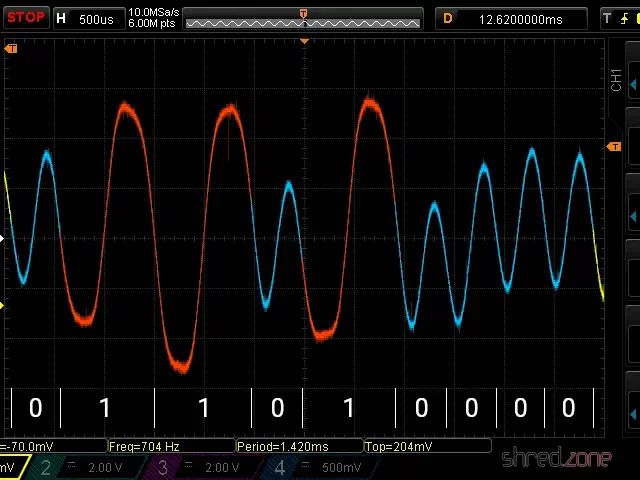
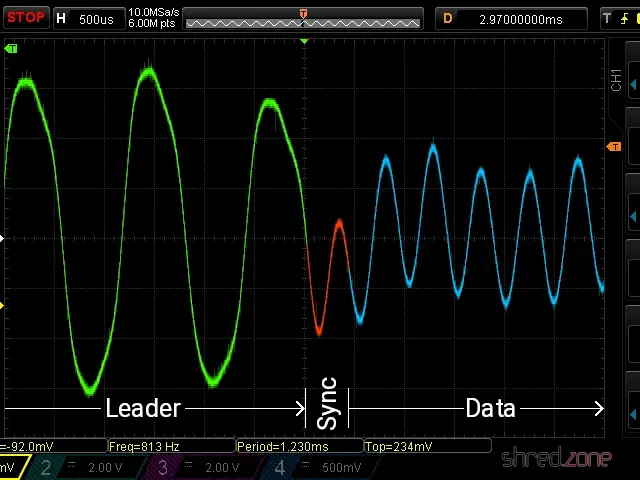
Aus diesem Grund beginnt die Aufnahme mit einem Vorlaufsignal (Leader), gefolgt von einem Synchronisationswellenzyklus (Sync), gefolgt vom eigentlichen Bitstrom. Das Vorlaufsignal ist lediglich eine kontinuierliche Welle mit einer Impulslänge von 2.168 T-States, was einen 806-Hz-Ton ergibt, der durch rote und cyanfarbene Ränder auf dem Fernseher angezeigt wird. Der Sync-Wellenzyklus ist ein Impuls von 667 T-States “an”, gefolgt von 735 T-States “aus”. Danach beginnt der eigentliche Datenstrom, der in blauen und gelben Randfarben angezeigt wird. Wenn das letzte Bit übertragen wurde, endet der Datenstrom einfach.
Wenn der ZX Spectrum also eine Datei von Kassette lädt, wartet er zuerst auf das 806-Hz-Vorlaufsignal. Wenn es für mindestens 317 ms erkannt wurde, wartet er auf die Sync-Impulse und beginnt dann, die Bitsequenz zu lesen, bis es beim Warten auf den nächsten Impuls zu einem Timeout kommt.
Es ist eine sehr einfache Methode, um Daten auf Kassette zu speichern. Und dennoch ist sie erstaunlich zuverlässig. Nach 30 Jahren konnte ich recover almost all files von meinen alten Kassetten wiederherstellen. Einige davon waren von den billigsten Marken, die ich 1987 in die Finger bekommen konnte.
Der einzige Nachteil ist, dass diese Methode sehr langsam ist. Mit 489 µs für eine “0” und 978 µs für eine “1” kann das Speichern von nur 48 KBytes an Daten bis zu 6 Minuten dauern, was eine durchschnittliche Bitrate von 1.363 bps (ja, Bits pro Sekunde) ergibt. Wenn wir eine einzige 3 MBytes große mp3-Datei auf diese Weise speichern würden, würde das fast 5 Stunden dauern (und 5 Kassetten mit jeweils 60 Minuten Aufnahmezeit erfordern).
Einige kommerzielle Spiele verwendeten Speedloader und Kopierschutzmechanismen. Speedloader reduzierten einfach die Anzahl der T-States für die Impulse, was die Bitrate erhöhte. Einiger Kopierschutz verwendete einen “klickenden” Vorlaufton, bei dem das Vorlaufsignal unterbrochen wurde, bevor die minimale Erkennungszeit von 317 ms erreicht war. Die originale Laderoutine konnte sich nicht auf diese Art von Signalen synchronisieren, weshalb es unmöglich war, diese Dateien in Kopierprogramme einzulesen. Diese Schutzmaßnahmen konnten zwar umgangen werden, indem man direkt von Kassette zu Kassette kopierte, aber das funktionierte aufgrund des zunehmenden Audiorauschens nur wenige Male.
Im nächsten Artikel werde ich mir den Inhalt des Bitstroms genauer ansehen, und ich werde dir auch erklären, woher der gefürchtete “R Tape loading error” kommt.
 Vor einigen Tagen habe ich meinen tzxtools einen Z80-Disassembler hinzugefügt. Da ich keinen für Python finden konnte, beschloss ich, meinen eigenen zu schreiben. Das Ergebnis passt in eine einzige Python-Quelldatei. Dieser Artikel ist das Making-of…
Vor einigen Tagen habe ich meinen tzxtools einen Z80-Disassembler hinzugefügt. Da ich keinen für Python finden konnte, beschloss ich, meinen eigenen zu schreiben. Das Ergebnis passt in eine einzige Python-Quelldatei. Dieser Artikel ist das Making-of…
Der Zilog Z80 ist ein 8-Bit-Prozessor. Das bedeutet, dass (fast) alle Befehle nur 1 Byte verbrauchen. Zum Beispiel hat der Befehl ret (Rücksprung aus dem Unterprogramm) C9 als Byte-Darstellung. Einigen Befehlen folgt ein weiteres Byte (als zu verwendende Konstante oder als relativer Sprungabstand) oder zwei weitere Bytes (als 16-Bit-Konstante oder absolute Adresse). Einige Beispiele:
C9 | -- | -- | -- | ret | Rücksprung aus dem Unterprogramm |
3E | 23 | -- | -- | ld a,$23 | Lade Konstante $23 in das A-Register |
C3 | 34 | 12 | -- | jp $1234 | Springe zu Adresse $1234 |
Beachte, dass bei 16-Bit-Konstanten die Bytes im Speicher scheinbar vertauscht sind. Das liegt daran, dass der Z80 eine sogenannte Little-Endian-CPU ist, bei der das niederwertige Byte zuerst kommt. Einige andere Prozessorfamilien (wie der 68000) sind Big-Endian und speichern das höherwertige Wort zuerst.
Es gibt also nur 256 Befehle, was es ziemlich einfach macht, sie zu disassemblieren. Ich habe ein Array mit 256 Einträgen verwendet, wobei jeder Eintrag den Befehl des jeweiligen Bytes als String enthält. Für Konstanten habe ich Platzhalter wie “##” oder “$” verwendet. Wenn ein solcher Platzhalter nach der Dekodierung im Befehlsstring gefunden wird, wird die entsprechende Anzahl von Bytes abgerufen und der Platzhalter durch den gefundenen Wert ersetzt.
Wenn wir einen Disassembler für die 8080-CPU schreiben würden, wären wir jetzt fertig. Allerdings hat der Z80 einige Erweiterungen, die abgedeckt werden müssen, nämlich zwei erweiterte Befehlssätze und zwei Indexregister.
Ein Satz erweiterter Befehle wird durch ein $ED-Präfix ausgewählt und enthält selten verwendete Befehle. Der andere Befehlssatz wird durch ein $CB-Präfix ausgewählt und verfügt über Bit-Manipulationen und einige Rotationsbefehle.
ED | B0 | -- | -- | ldir | Kopiere BC Bytes von HL nach DE |
ED | 4B | 78 | 56 | ld bc,($5678) | Lädt den Wert von Adresse $5678 in das BC-Registerpaar |
CB | C7 | -- | -- | set 0,a | Setze Bit 0 im A-Register |
Für das $ED-Präfix habe ich ein separates Array zur Dekodierung der Befehle verwendet. Die $CB-Befehle folgen einem einfachen Bit-Schema, sodass die Befehle durch ein paar Zeilen Python-Code dekodiert werden konnten.
Der Z80 bietet zwei Indexregister namens IX und IY. Sie werden verwendet, wenn dem Befehl ein $DD- bzw. $FD-Byte vorangestellt ist. Diese Präfixe verwenden im Grunde das ausgewählte Indexregister anstelle des HL-Registerpaars für den aktuellen Befehl. Wenn jedoch der Adressierungsmodus (HL) verwendet wird, wird ein zusätzlicher Byte-großer Offset bereitgestellt. Die Indexregister können mit dem $CB-Präfix kombiniert werden, was die Dinge kompliziert machen kann.
E5 | -- | -- | -- | push hl | Lege HL auf den Stack |
DD | E5 | -- | -- | push ix | Lege IX auf den Stack (gleicher Opcode E5, aber jetzt mit DD-Präfix) |
FD | E5 | -- | -- | push iy | Lege IY auf den Stack (jetzt mit FD-Präfix) |
FD | 21 | 80 | FF | ld iy,$FF80 | Lade Konstante $FF80 in das IY-Register |
DD | 7E | 09 | -- | ld a,(ix+9) | Lade Wert an Adresse IX+9 in das A-Register (Offset ist nach dem Opcode) |
CB | C6 | -- | -- | set 0,(hl) | Setze Bit 0 an der Adresse in HL |
FD | CB | 03 | C6 | set 0,(iy+3) | Setze Bit 0 an der Adresse IY+3 (Offset ist vor dem Opcode) |
Wenn der Disassembler ein $DD- oder $FD-Präfix erkennt, setzt er ein entsprechendes ix- oder iy-Flag. Später, wenn der Befehl dekodiert wird, wird jedes Vorkommen von HL entweder durch IX oder IY ersetzt. Wenn (HL) gefunden wurde, wird ein weiteres Byte aus dem Bytestream geholt und als Index-Offset für (IX+dd) oder (IY+dd) verwendet.
Es gibt eine Ausnahme. Die obigen Beispiele zeigen, dass der Index-Offset immer beim dritten Byte zu finden ist. Das bedeutet, dass, wenn das Indexregister mit einem $CB-Präfix kombiniert wird, der eigentliche Befehl nach dem Index steht. Dies ist ein Fall, der in meinem Disassembler eine Sonderbehandlung benötigte. Wenn diese Kombination erkannt wird, wird der Index-Offset abgerufen und gespeichert, bevor der Befehl dekodiert wird.
Puh, das war kompliziert. Jetzt sind wir in der Lage, den offiziellen Befehlssatz der Z80-CPU zu disassemblieren. Aber wir sind noch nicht fertig. Es gibt eine Reihe von undokumentierten Befehlen. Der Hersteller Zilog hat sie nie dokumentiert, sie sind nicht sonderlich nützlich, aber sie funktionieren trotzdem auf fast jeder Z80-CPU und werden tatsächlich verwendet.
Die meisten von ihnen werden einfach durch die Erweiterung der Befehls-Arrays abgedeckt. Zusätzlich wirken sich die $DD- oder $FD-Präfixe nicht nur auf das HL-Registerpaar aus, sondern auch nur auf die H- und L-Register, was IXH/IYH- und IXL/IYL-Register ergibt. Dies wird durch die Nachbearbeitung der Befehle abgedeckt. Ein ganz besonderer Fall ist das $CB-Präfix in Kombination mit Indexregistern, was eine ganze Reihe neuer Befehle ergibt, die das Ergebnis einer Bit-Operation in einem anderen Register speichern. Dies erforderte tatsächlich eine Sonderbehandlung durch einen separaten $CB-Präfix-Befehlsdekodierer.
Schließlich wird der ZX Spectrum Next einige neue Befehle wie Multiplikation oder Hardware-bezogene Dinge für den ZX Spectrum bringen. Auch diese wurden durch die Erweiterung der Befehls-Arrays abgedeckt. Die einzigen Ausnahmen sind der Befehl push [const], bei dem die Konstante als Big-Endian gespeichert wird, und der Befehl nextreg [reg],[val], dem (als einzigem Befehl) zwei Konstanten folgen.
Und das war’s. 😄 So schreibt man an einem einzigen Nachmittag einen Z80-Disassembler.
Der ZX Spectrum war ein vergleichsweise günstiger Heimcomputer, und daher waren die Kassetten-Lade- und Speichermechanismen nicht besonders hochentwickelt. Die Kassettenaufnahme ist lediglich ein Datenstrom aus kurzen Wellen (0-Bit) und langen Wellen (1-Bit). Der Datenstrom beginnt mit einem Vorlaufsignal (einer Reihe von noch längeren Wellen) und einem einzelnen Synchronisationsimpuls. Theoretisch bedeutet das Einlesen einer Kassettenaufnahme also, einzelne Wellenlängen zu messen, indem man die Zeit zwischen zwei Nulldurchgängen misst und sie in eine Folge von Bytes umwandelt.
Aber wir haben es hier eben mit analoger Technik aus den 1980er Jahren zu tun. In der Praxis wirst du Signale wie dieses finden. Ein Knacken hat einen zusätzlichen Nulldurchgang erzeugt, der ignoriert werden muss. Außerdem ändern sich die Amplituden und DC-Offsets ständig.
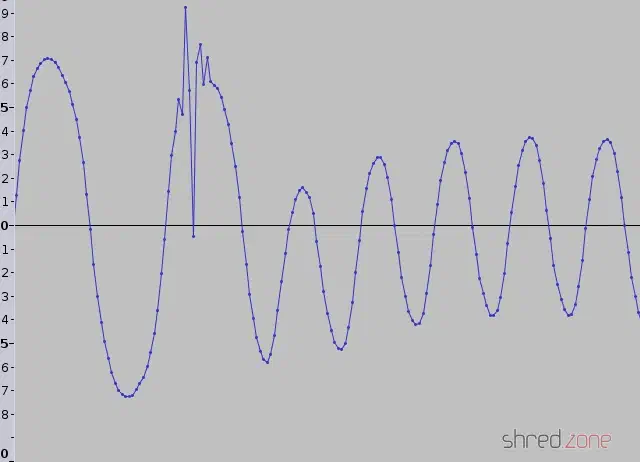
Und puff… Da verging wieder eine Woche mit nächtlichem Hacken von Python-Code, dem ganz genauen Betrachten von Audiowellen und der Suche nach Hinweisen, warum tzxwav sich nicht so verhält, wie ich es erwarte. Aber ich denke, das Ergebnis kann sich jetzt sehen lassen! tzxwav liest jetzt fast alle meine Kassetten-Samples ohne diese gefürchteten CRC-Fehler. Wenn es CRC-Fehler gibt, war das Sample normalerweise so stark beschädigt, dass es einer manuellen Restaurierung bedarf.
Und als Bonus ist es jetzt fast doppelt so langsam wie vorher. 🤭 Aber Geschwindigkeit war ohnehin nie ein Ziel, da du deine alten Kassetten wahrscheinlich nur einmal konvertieren wirst.
 Da ich in der Stimmung für ordentlich ZX Spectrum Retro-Action bin, habe ich all meine alten Computerkassetten hervorgekramt, in dem Versuch, sie zu digitalisieren und zu konvertieren. Es stellte sich heraus, dass das schwieriger war als gedacht…
Da ich in der Stimmung für ordentlich ZX Spectrum Retro-Action bin, habe ich all meine alten Computerkassetten hervorgekramt, in dem Versuch, sie zu digitalisieren und zu konvertieren. Es stellte sich heraus, dass das schwieriger war als gedacht…
Das erste Problem bestand darin, einen Kassettenspieler zu finden. Ich hatte meinen letzten Kassettenrekorder vor ein paar Jahren entsorgt. Die neuen, die ich bei Amazon fand, sahen auf den ersten Blick ganz nett aus. Man konnte sie an den USB-Anschluss anschließen oder die Kassetten sogar direkt auf einen USB-Stick digitalisieren. Die Kundenbewertungen waren jedoch abschreckend: billiges Plastik, schlechter Klang, das Digitalisieren auf einen USB-Stick war nur im Batteriebetrieb möglich… Mehr Glück hatte ich bei eBay, wo ich einen echten Aiwa-Walkman aus den 1990er Jahren (es ist sogar ein Rekorder, mit Auto-Reverse und Dolby NR) in gutem Zustand für ungefähr denselben Preis fand.
Ich schloss den Walkman mit einem Kabel mit 3,5-mm-Stereo-Klinkensteckern an den Mikrofoneingang meines Computers an, wählte den richtigen Kassettentyp (Normal oder CrO2) und schaltete Dolby NR aus. Dann legte ich direkt mit dem Digitalisieren los und verwendete Audacity für die Aufnahme und Nachbearbeitung. Ich nutzte 16 Bit pro Kanal und eine Abtastrate von 44100 Hz. Der ZX Spectrum lieferte ein Monosignal, also wählte ich den linken oder rechten Kanal (je nach Qualität) und verwarf den anderen. Das Heruntermischen des Stereosignals erwies sich als problematisch, ebenso wie die Verwendung eines verlustbehafteten Dateiformats wie ogg.
Die WAV-Dateien lassen sich in den Fuse Emulator laden, aber es ist besser, sie in TZX-Dateien zu konvertieren, da diese viel kleiner sind. Dafür gibt es einige Tools, zum Beispiel audio2tape, das mit Fuse mitgeliefert wird. Ich war jedoch mit dem Ergebnis nicht zufrieden, da die generierten TZX-Dateien viele CRC-Fehler enthielten. MakeTZX ist ebenfalls einen Versuch wert, da es digitale Filter unterstützt, aber ich habe es unter Linux nicht zum Laufen gebracht. Einige andere Konverter-Tools gibt es nur für Windows und sind daher nicht besonders interessant. 😉
Also habe ich angefangen, eine Reihe von TZX tools in Python zu schreiben. Darin ist tzxwav enthalten, ein weiteres Tool zur Konvertierung von WAV- in TZX-Dateien, das jedoch robust gegenüber schlechter Audioqualität ist. Es kostete mich drei Wochen Arbeit und etwa 30 Stunden Bandmaterial, bis es in der Lage war, fast alle meine Kassettenaufnahmen erfolgreich zu lesen.
Ein Vorteil von TZX-Dateien ist, dass sie die rohen ZX Spectrum-Binärdateien enthalten, sodass sie sehr leicht zu extrahieren sind. Mit tzxcat lassen sich einzelne Binärdateien aus TZX-Dateien abrufen, die dann in PNG-Dateien, BASIC-Quelltexte oder was auch immer umgewandelt werden können, vorausgesetzt, es gibt Konverter dafür.
Was ich jetzt habe, sind TZX-Dateien von all meinen alten ZX Spectrum-Kassetten. Es war sehr interessant, meine alten Dateien, Bildschirme, Programme und Quellcodes wiederzuentdecken. In den Jahren 1987 und 1988 habe ich viele mehr oder weniger nützliche Tools geschrieben, verschiedene Schriftarten entworfen und zwei Demos fertiggestellt.
 Auf einem langsamen Prozessor wie dem Z80 ist es unerlässlich, über die Ausführungszeit nachzudenken. Oft ist ein sauberer Ansatz zu langsam, und man muss den Code optimieren, um ihn viel schneller zu machen.
Auf einem langsamen Prozessor wie dem Z80 ist es unerlässlich, über die Ausführungszeit nachzudenken. Oft ist ein sauberer Ansatz zu langsam, und man muss den Code optimieren, um ihn viel schneller zu machen.
Die ZX Spectrum Bildschirm-Bitmap ist nicht linear. Die 192 Pixelzeilen sind in drei Abschnitte von 64 Pixelzeilen unterteilt. In jedem dieser Abschnitte kommen zuerst alle 8 ersten Pixelzeilen, gefolgt von den zweiten Pixelzeilen und so weiter. Der Vorteil ist, dass man beim Schreiben von Zeichen in die Bitmap nur das H-Register inkrementieren muss, um die nächste Bitmap-Zeile zu erreichen. Der Nachteil ist, dass eine pixelgenaue Adressberechnung die Hölle ist.
So werden die Koordinaten eines Pixels auf die Adresse abgebildet:
| H | L | ||||||||||||||
| 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 1 | 0 | Y7 | Y6 | Y2 | Y1 | Y0 | Y5 | Y4 | Y3 | X7 | X6 | X5 | X4 | X3 |
X2, X1 und X0 repräsentieren die Bitnummer an der Adresse. Sie können als Zähler für Rechts-Shift-Operationen verwendet werden.
Mein erster Versuch war ein geradliniger Code, der die Bitgruppen verschob, maskierte und an die richtigen Stellen bewegte. Er benötigte 117 Zyklen. Das ist nett, aber wir können es besser machen.
Wir brauchen viele Rotationsoperationen, um die Bits an die richtige Position zu schieben. Die Rotation ist eine ziemlich teure Operation auf einem Z80, da es keine Befehle gibt, die um mehr als ein Bit auf einmal rotieren. Meine Idee war, die X-Koordinate durch 8 zu teilen (indem ich sie dreimal nach rechts rotiere) und gleichzeitig Y3 bis Y5 in das L-Register zu schieben. Mit einem ähnlichen Trick konnte ich Bit 14 während des Rotierens setzen, was mir eine weitere or-Operation mit einer Konstanten ersparte.
Dies ist der finale optimierte Code. Er nimmt die X-Koordinate im C-Register und die Y-Koordinate im B-Register. Die Bildschirmadresse wird im HL-Registerpaar zurückgegeben. BC und DE bleiben unverändert, also gibt es keinen Bedarf für teure push- und pop-Operationen.
pixelAddress: ld a, b
and %00000111
ld h, a ; h enthält Y2-Y0
ld a, b
rra
scf ; Bit 14 setzen
rra
rra
ld l, a ; l enthält Y5-Y3
and %01011000
or h
ld h, a ; h ist jetzt komplett
ld a, c ; X durch 8 teilen
rr l ; und Y5-Y3 hineinrotieren
rra
rr l
rra
rr l
rra
ld l, a ; l ist jetzt komplett
ret
Er benötigt nur 108 Zyklen, inklusive ret. Die Optimierung hat mir 9 Zyklen (oder etwa 8%) gespart. Das klingt nicht nach viel, aber wenn der Code in einer Schleife aufgerufen wird, werden diese 9 Zyklen mit der Anzahl der Schleifendurchläufe multipliziert.
Ich behaupte, dies ist die schnellste Lösung, ohne auf eine Lookup-Tabelle zurückzugreifen. Versuch mich zu schlagen! 😁